Cycles Sampling Patterns¶
Overview¶
Sampling patterns are essential in Monte Carlo rendering. Pseudo-random numbers are simple and converge to the correct result. But we can do better with low discrepancy sequences.
Cycles supports adaptive sampling, and for that reason sampling patterns must support progressively taking more samples without the effective number of pixel samples being known in advance.
Two sampling patterns are supported: Progressive Multi-Jittered and Sobol.
API¶
The simplest API would be to have a function like this
This would give us the random number for a given sample without having
to maintain any kind of state. The sample here is the rendering
sample, which is increased each time a new sample is taken for that
pixel. The pixel_hash is a unique random integer for each pixel, to
decorrelate patterns between neighboring pixels.
The dimension require more explanation. We give each random number
used in tracing a path a well defined unique dimension. We have two
dimensions for the pixel filter, two for depth of field, and then for
each bounce, one to pick a BSDF, two to sample the BSDF, ... .
enum PathTraceDimension {
PRNG_FILTER_U = 0,
PRNG_FILTER_V = 1,
PRNG_LENS_U = 2,
PRNG_LENS_V = 3,
PRNG_BASE_NUM = 4,
PRNG_BSDF_U = 0,
PRNG_BSDF_V = 1,
PRNG_BSDF = 2,
PRNG_LIGHT = 3,
PRNG_LIGHT_U = 4,
PRNG_LIGHT_V = 5,
PRNG_LIGHT_F = 6,
PRNG_TERMINATE = 7,
PRNG_BOUNCE_NUM = 8
};
From this we can easily compute the dimension each time we need to get a random number from the generator, for example:
It's important the dimension matches consistently across paths so that the sampling pattern is used on the same surface or volume when possible.
Progressive Multi-Jittered¶
The progressive multi-jittered (PMJ) sampler is based on the paper on Progressive Multi-Jittered Sample Sequences. The implementation currently uses 1 64x64 (4096 samples) table to look up the values for the PMJ sequence (as it takes to long to generate these on the fly) whereas in the implementation in the paper they use multiple tables of 4096 samples to decorrelate between dimensions.
Instead the implementation uses Cranley-Patterson rotation to displace the sample pattern to avoid correlation issues as this resulted in faster sample generation. Additionally, the sample order is shuffled using a nested uniform scramble based on Practical hash based Owen scrambling to provide further decorrelation. This implementation also differs from the paper in that currently it does not stratify across 4D and instead only uses 2D to save memory and increase performance. The implementation provides 2 functions.
The convergence of this implementation has been analyzed and compared to the existing Sobol implementation described below. To generate the results the Sobol implementation was used to generate a reference image using 131072 samples. Then images were generated at going from 2 to 2048 samples and the results put into a graph. The results are presented below
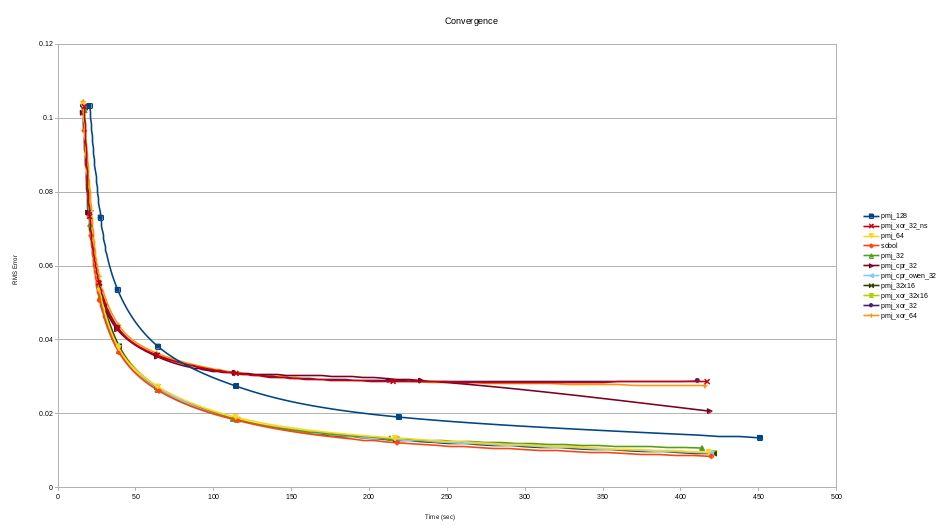
The graph shows various configurations of the PMJ sampler the one currently in use is the pmj_64 which is the implementation described above.
ccl_device float pmj_sample_1D(const KernelGlobals *kg, uint sample, uint rng_hash, uint dimension);
ccl_device void pmj_sample_2D(const KernelGlobals *kg, uint sample, uint rng_hash, uint dimension, float *x, float *y);
This first gives a single sample for 1 dimension and the other for sampling 2 dimensions.
Sobol¶
Sobol sequences have the property that they can be used for progressive sampling. Unlike the Halton sequence that can also be used for this, they are not correlated in higher dimensions, and so do not need to be scrambled. Any number from any dimension can be queried without per path precomputation.
Each dimension has it's own sequence, and when rendering the i-th pass, we get element i from the sequence. A sequence is defined by a 32x32 binary matrix, and getting the i-th element in the sequence corresponds to multiplying the matrix by i. With binary operations this ends up being pretty quick:
float sobol(unsigned int vectors[][32], unsigned int dimension, unsigned int i)
{
unsigned int result = 0;
for(unsigned int j = 0; i; i >>= 1, j++)
if(i & 1)
result ^= vectors[dimension][j];
return result * (1.0f/(float)0xFFFFFFFF);
}
These matrices are not as simple to compute, but luckily the hard work has been done for us, and the data to generate them up to dimension 21201 is available online.
We currently use 4 dimensions initially to sample the subpixel location and lens and 8 numbers per bounce, so that limits us to a maximum path depth of 2649.
At the moment we are using the same sequences in each pixel, decorrelated using a Cranly-Patterson rotation (a simple random 2D shift different for each pixel). This may not be optimal, and there's some experiments in the code with full screen nets, but they give too much correlation.
Adaptive Sampling¶
Only PMJ is currently supported for adaptive sampling. Adaptive sampling works by accumulating two render passes, one with all samples and one with half the samples, and computing the difference between them to estimate the error.
Selecting an appropriate half of the sample pattern is currently only supported for PMJ.
Sample Reuse¶
Random numbers can sometimes be reused for multiple decisions, which can
both with performance and distribution. For example if we choose between
two sampling strategies, we may split the [0..1] range into two
intervals [0..r] and [r..1] around the random number, one
for each strategy, and then rescale the interval back. This ensure that
each strategy gets a well distributed subset of the sampling pattern,
which would not be the case if we used two separate dimensions for
picking the strategy and sampling.
References¶
- Correlated Multi-Jittered Sampling
- Progressive Multi-Jittered Sample Sequences
- Stochastic Generation of (t, s) Sample Sequences
- Efficient Multidimensional Sampling
- Strictly Deterministic Sampling Methods in Computer Graphics
- Quasi-Monte Carlo Light Transport Simulation by Efficient Ray Tracing
- Motion Blur Thesis
- A Hierarchical Automatic Stopping Condition for Monte Carlo Global Illumination