RNA¶
Implementation¶
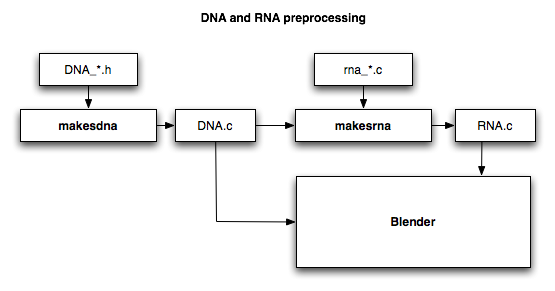
The implementation is in the makesrna module. The important files to understand the system are:
RNA_types.h: The important RNA data structures are defined here.
RNA_access.h: API for accessing structs and properties at runtime.
RNA_define.h: API for defining structs and properties.

Defining Structs and Properties¶
Structs and their properties are defined in rna_*.cc files in the
makesrna module, and the definitions are generated as part of the build
system. Errors will be printed during build and will help debugging.
Struct¶
- If you are not adding it to an existing file:
- Copy an existing file, rename and clean it up.
- In makesrna.cc, add it to the
PROCESS_ITEMSlist.
- In rna_access.h, add the extern StructRNA declaration.
- For a datablock, add the proper ID_ case to the rna_ID_refine() function in rna_ID.cc
Next in the RNA_def_* function the struct must be defined.
RNA_def_struct defines the struct itself. We must define an
identifier which is a unique name and used for identifying the struct
in code, and a name which is a human readable name.
The system will automatically try to find a corresponding DNA struct
with the same name as the identifier. If there is a corresponding DNA
struct but it has a different name, RNA_def_struct_sdna can be used to
pass the right name, this is important for defining properties more
automatic later.
For each struct it is also possible to set a string property as being the name of that struct, which will be used in the UI and for doing string lookups in collections.
For ID struct, it is also necessary to:
- In rna_main.cc, and either change an existing entry in the "lists" array to the right type instead of "ID", or add a new entry.
- Add the struct in rna_ID_refine in rna_ID.cc
Property¶
For each property we start with RNA_def_property. A identifier must
be specified similar to a struct. Next to that we have to define a
type and a subtype. The type defines the data type, the subtype
gives some interpretation of the data, for example a float array
property may be a color, a vector or a matrix.
Again the system will try to find a property with the same name as the
identifier in the DNA struct, if it has a different name, the next
thing to do is to correct specify it with a RNA_def_*_sdna function.
This DNA information is used to derive various things like a get/set
function or iterators for collections, array length, limits, etc, and
rules for how the mapping works are explained in the next section.
It is possible to override these afterwards if the automatic values are
not correct. The file RNA_define.h gives an overview of the
information that can be supplied for the different types. Important
things to define are the array length, range for numbers, and items for
an enum.
Next we have to define a default value. If not defined explicitly it is
assumed to be 0 for numbers, "" for strings, NULL for pointers and
an empty collection.
For building UI's more automatic also a human readable name and description for tooltips are defined. For numbers a soft range, stepsize for dragging and precision can be defined. These will be the default values when making buttons from RNA properties.
In many cases the automatic DNA matching will take care of this, but in
other cases we must next define callback functions for get/set
functions. Their names can be passed with the RNA_def_property_*_funcs
functions, see RNA_types.h for their arguments. Collections are the
most difficult, though ListBase and typical arrays can be
automatically supported. Note that some function calls are optional, and
will only help in optimization, for example the lookup functions for
lists.
DNA Matching¶
- Booleans/Ints/Floats: array length based on the value
xinfloat member[x];for example, only one dimensional arrays supported. In case the variable itself is not an array, it will assume the consecutive variables to be part of the array. For example by specifyingrfromfloat r, g, b;it would assume the address of the array to be&r. - Booleans can specify a bit in
RNA_def_property_boolean_sdna. With an array length defined but no array SDNA member it is assumed the array is defined by bitflags starting from the specified bit. - Ints: data range defaults to
INT_MIN/INT_MAX, unless a char or short is detected in which case their range is used. Unsigned types are not detected automatic currently (SDNA doesn't provide them), so thePROP_UNSIGNEDsubtype or a manual range should be used for those. - Enums:
RNA_def_property_enum_sdnahas a parameter to assume the enum values are bitflags, which should be set in case the enum is mixed with other flags. - Strings: char arrays are recognized and the maximum length is based on the array size.
- Pointers: the pointer type is automatically defined if it is not set yet, based on the DNA correspondence of structs. For Collections defined as a pointer to an array the pointer is also used.
- Collections: a
ListBaseis recognized andbegin/next/getfunctions are automatically generated based on this. - Collections: when passing along the name of a variable that contains
the length of the collection to the sdna function, it is assumed that
an array is being used, and the
begin/next/get/endfunctions for the array will be autogenerated. If the pointer of the member is a single pointer likeMVert *mvert;, it will return&mvert[i]as items, if it is a double pointer likeMaterial **mat;, it will returnmat[i]as items. - Members in a nested struct can be recognized, when passing
RNA_def_property_*_sdnaa value liker.cfraortoolsettings->unwrapperfor example.
Naming Conventions¶
Structs¶
- identifier: use CamelCase, for example "Material", "NodeTree". The identifier should be a valid name for use in python code.
- name: use capital letters with spaces, for example "Material", "Node Tree".
Properties¶
- Don't shorten names unnecessarily. Often this is done in buttons to save space and because it is possible to derive the meaning from the context, however this depends on the button layout and so should not necessarily be done in RNA.
- Avoid negative names like "No Vertex Normal Flip", in that case change the boolean to "Vertex Normal Flip".
- identifier: use lower_case with underscores, for example "alpha", "diffuse_color". The identifier should be a valid name for use in python code, i.e. no spaces, don't start it with a number, ...
- name: use capital letters with spaces, for example "Alpha", "Diffuse Color".
- description: only make one if it is not obvious, if it just repeats the name or is something like "Location of the Vertex" it is not useful anyway. Write as sentence(s) with typical capitalization.
Property Abbreviations¶
Here is a list of abbreviations accepted for property names
- minimum/maximum -> min/max
- coordinates -> co
Property Prefixes/Suffixes¶
-
property word ordering should be from most to least significant. eg.
min_x, offset_x, lock_y
rather then...xmin, x_min, y_offset-
- Booleans
- Should have the prefix
- use_ common prefix to denote if an option is used.
- use_only_ same as use_ but denotes exclusivity.
- show_ for drawing options or interface display toggles.
- show_only_ same as show_ but denotes exclusivity.
- is_ for read-only checks is_saved, is_valid.
- lock_ for options which lock functionality. lock_x
- invert_ for options which invert functionality.
Examples of names that should have the prefix. use_texture, use_border, use_mipmaps
Exceptions for boolean prefix
- select used everywhere, obviously describes a selection boolean
- hide similar to selected, used for hiding data.
- layer an array of booleans for object and bone layers.
- state an array of booleans for the game engine.
-
- Float values from 0.0 to 1.0 can the suffix _factor.
This is better for the following cases.
reflection->reflect_factor, glossiness->gloss_factor
File and Path Names¶
strings that deal with file paths have the following conventions
- filepath: the full path to a file.
- filename: the name of a file with no directory component.
- path: the path to a directory or an ambiguous location on the filesystem.
Enum Items¶
- identifier: use UPPER_CASE with underscores.
- name: use capital letters with spaces, for example "Conformal", "Angle Based".
Internals¶
The RNA defitions are generated in a way similar to DNA preprocessing, in advance as part of the build system. Such a preprocessing step avoids manually writing much API code, taking advantage of the available information from the DNA system. Also it should avoid startup overhead since the result of the definitions would be baked into the source code. For python/plugin ID properties however this would still need to be done at runtime, though the code currently those not support that.
The definition is separate from the DNA files instead of embedded in comments, as in earlier other proposals. This is necessary because structs/properties do not necessarily have a one-to-one mapping with DNA structs/members. Multiple properties might be part of one DNA struct member, for example in the case where booleans are stored as bitflags. And one property might be based on multiple DNA struct members, for example a mesh vertex collection which consists of both mvert and totvert.
The autogenerated code currently goes into a single RNA.c file. It would be possible to write this into existing files, in blenkernel for example, but it seems a bit risky and inconvenient doing this, if those files are being edited at the same time in an IDE for example.
Runtime Access¶
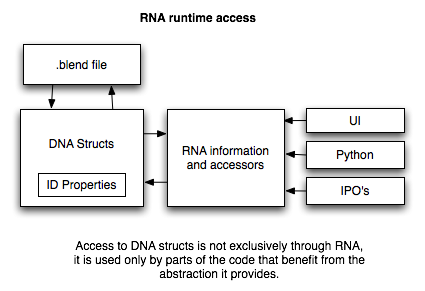
Runtime access to property values is done through the functions defined
in RNA_access.h. Basically get/set functions and a collection iterator
are provided.
There are also functions to check if the property is editable or evaluated. If the property is editable, that means it can be edited by the user. If it is evaluated, that means it can be set by some function as part of evaluations like modifiers, constraints, or other parts of the animation system. This can change depending if the property has an IPO for example.
Pointers¶
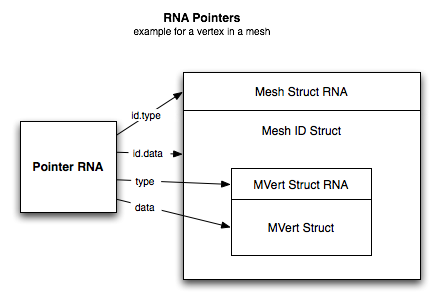
A pointer to an RNA struct is always wrapped in a PointerRNA struct.
This contains the actual data pointer and the struct type. It also
contains the data pointer and the type of the ID datablock that the data
belongs to. This is necessary in some cases, as for example a vertex by
itself does not provide enough information to update the dependency
graph, we need to know the mesh this vertex came from.
To create pointers at runtime, use the RNA_main_pointer_create,
RNA_id_pointer_create and RNA_pointer_create functions.
Property functions callbacks get such PointerRNA's instead of direct
pointers to the data, so that they can use the ID data if needed. The
pointer and collection get/set function callbacks return the data
pointer, the type and ID will be automatically filled in outside of the
callback.
ID Properties¶
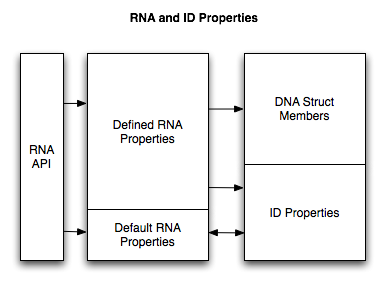
RNA also supports ID properties, in two ways:
- If an RNA property is defined at runtime, or with the
PROP_IDPROPERTYflag, an ID property will be created the first time that property is set through the RNA API. The RNA API will initially return the default value until the ID property is created, and afterward, the ID property value will be returned. Note that if there is an ID property with the same name but a different type than defined with RNA, it will be removed and overwritten to match the RNA type. - If an ID property exists but there is no corresponding RNA property, it will be still be exposed through RNA when iterating over the properties in a struct. The RNA information will then get default values: things like user interface name will be taken from the ID property name, and number ranges for example will be the default values for that type.
To simplify the API for ID properties for which there is no
corresponding RNA property, RNA_property_* functions can accept
either an actual PropertyRNA *, or an IDProperty * that was cast
to a PropertyRNA *. Internally functions will detect which data
structure is used. For this reason access to PropertyRNA * members
must go through accessor functions rather than directly accessing the
members.
Operators¶
The inputs of operators are defined with RNA at runtime, and so
corresponding ID properties will be automatically created. An API for
easily accessing these properties by name is defined in RNA_access.h,
with functions like RNA_float_set(op->ptr, "value", 3.1415f); and
RNA_float_get(op->ptr, "value");
When registering the operator the RNA struct will be automatically
creating, only the properties have to be created for the struct pointed
to by ot->srna.
Updates¶
When RNA properties are set, updates may be needed in Blender to ensure dependencies are correct or editors are redraw. Each property can have an associated update() function that is run after set(), and a notifier.
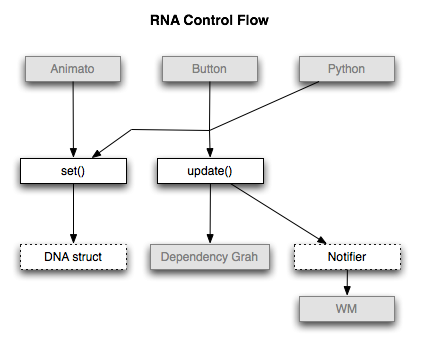
Experimental¶
RNA Path¶
The current code contains experimental functionality to refer to structs
and properties with a string, using a syntax like:
scenes[0].objects["Cube"].data.verts[7].co.
This provides a way to refer to RNA data while being detached from any particular pointers, which is useful in a number of applications, like UI code or Actions, though efficiency is a concern, and it not sure if this will end up being useful.
Dependencies¶
There are some property flags to indicate dependencies. How and if this will be used is not clear yet, though this could be an interesting system to generate dependency graphs more automatic. However there are some issues with this, for example the system cannot know if a modifier is disabled for example, and so it might count unnecessary dependencies, unless the dependency could also be checked runtime with a callback.
Additionally dependency graphs more fine grained than between full objects, and functionality like groups and proxies may be difficult to support, and the dependency graph may not be worth/feasible trying to change that much for 2.5.